




新闻中心
DELL服务器知识:看IPU如何重塑AI芯片格局(下)
英伟达公司率先于1999年提出GPU的概念,GPU使显卡减少了对CPU的依赖,然而随着模型越来越大,参数越来越多,面对高精度高吞吐量的需求,算力优势显著的IPU也许更能代表AI芯片的发展方向。
Graphcore IPU在现有以及下一代模型上的性能均优于GPU,在自然语言处理方面的速度能比GPU快25%到50%;在图像分类方面,吞吐量7倍于GPU,而且时延更低。
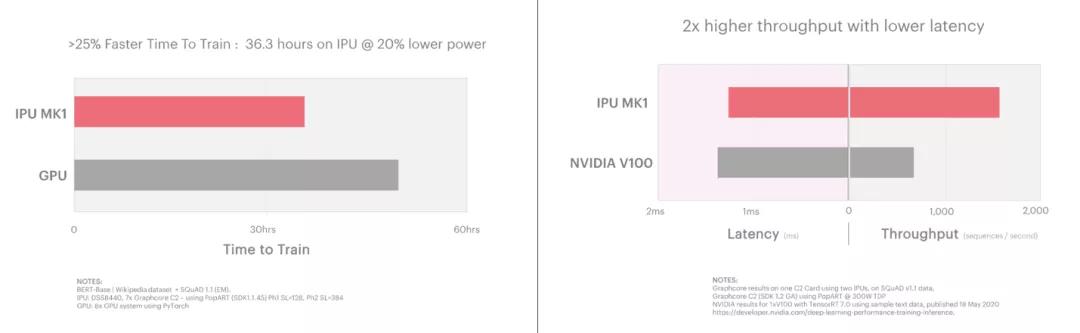
Natural Language Processing-BERT
BERT (Bidirectional Encoder Representations from Transformers)是目前使用NLP模型之一。IPU加速了BERT的训练和推理,在极低延迟的情况下, IPU能够进行实现2倍于目前解决方案的吞吐量,同时延迟性能比当前的解决方案提升1.3倍。
计算机视觉:EfficientNet & ResNeXt模型
由于IPU架构的特定特性,它非常擅长于分组卷积的模型。在计算机视觉模型如efficient entnet和ResNeXt中显著提升了训练和推理的性能。
在EfficientNet推理(左图)和训练(右图)模型测试中,IPU在比GPU延迟低14倍的情况下实现了15倍的高吞吐量的优势,推理模型种子能够实现7倍于目前GPU解决方案的吞吐量。

如下图所示,ResNeXt-101: Inference(左图) 和 ResNeXt-50 Training(右图)与GPU相比,Graphcore C2 IPU处理器在延迟低24倍的情况下实现了7倍的高吞吐量。

好马配好鞍——IPU全软件栈和框架支持
Graphcore提供了Poplar SDK IPU软件开发平台,帮助用户构建人工智能应用,可为当今的模型提供开箱即用的性能。
Poplar SDK可与TensorFlow、Pytorch和ONNX等流行框架一起使用。它支持高阶的机器智能图描述,可编译加载到IPU上优化的Poplar图和相关的控制程序。大规模的处理器内存意味着可以充分利用庞大的处理器内带宽,可将整个模型加载到IPU上。
Poplar SDK支持一系列标准框架。通过TensorFlow,Poplar SDK可直接接受XLA图,并将XLA编译输出为Poplar图和控制程序。
Graphcore还为ONNX提供了训练运行时(runtime),并且正与ONNX各组织紧密合作,以将其纳入ONNX标准环境中。





相关文章
- DELL服务器知识:看IPU如何重塑AI芯片格局(上)2021年01月10日
- 北京戴尔服务器|VxRail为何广受青睐,这份报告给您答案2021年01月05日
- 北京联想服务器代理商教您怎样进入ThinkSystem系列服务器SAS RAID阵列配置界面2020年12月11日
- 联想服务器所配备常见SAS RAID卡规格汇总2020年12月11日
- 浪潮AI服务器宣布支持NVIDIA新A100 80G GPU2020年11月18日



